Choosing a suburb by bike commute time
I recently moved to a new city, and I'm looking to live close enough to work that I can bike. Although I can eyeball on a map the straight-line commute distance for a potential house, often the actual time you'd spend biking it is quite different. Dedicated bike paths are super fast to ride, bypassing stop signs and traffic lights. While airports and highways can result in time-consuming detours.
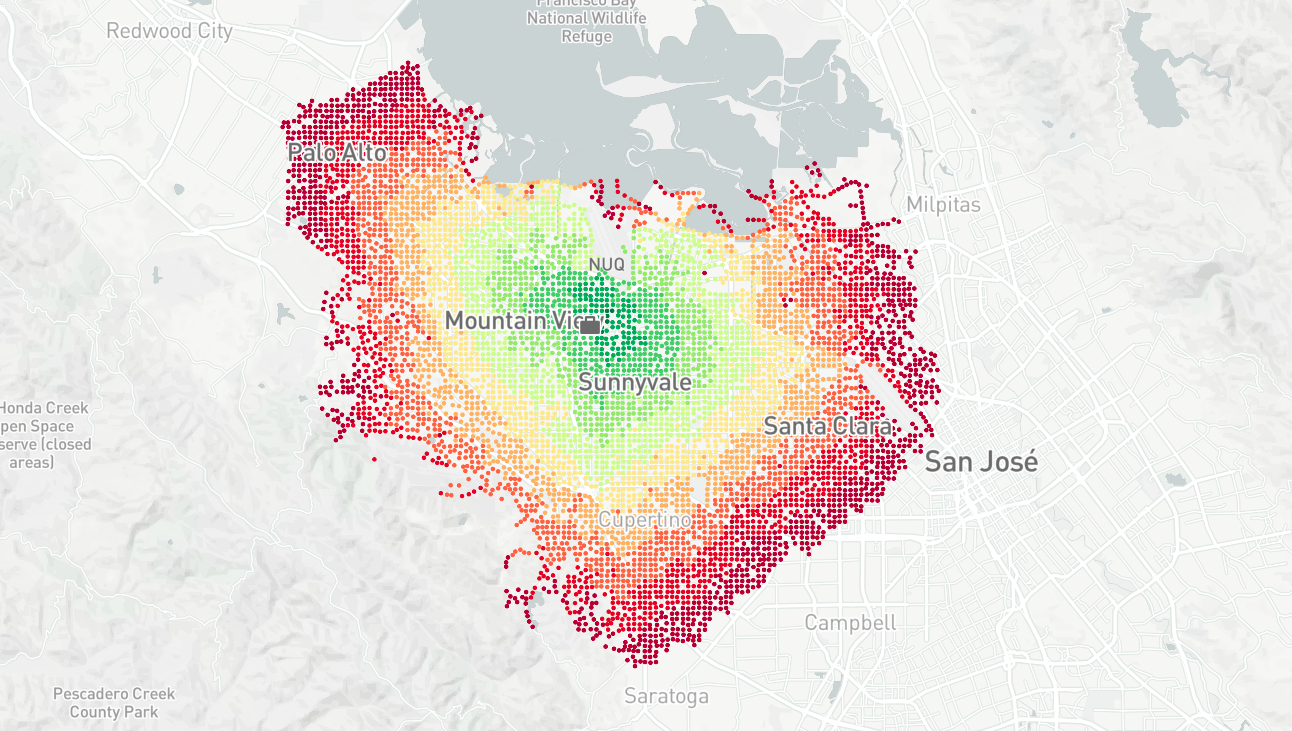
So I put together this map overlaying contours of equal commute time onto the streets and suburbs around Mountain View.
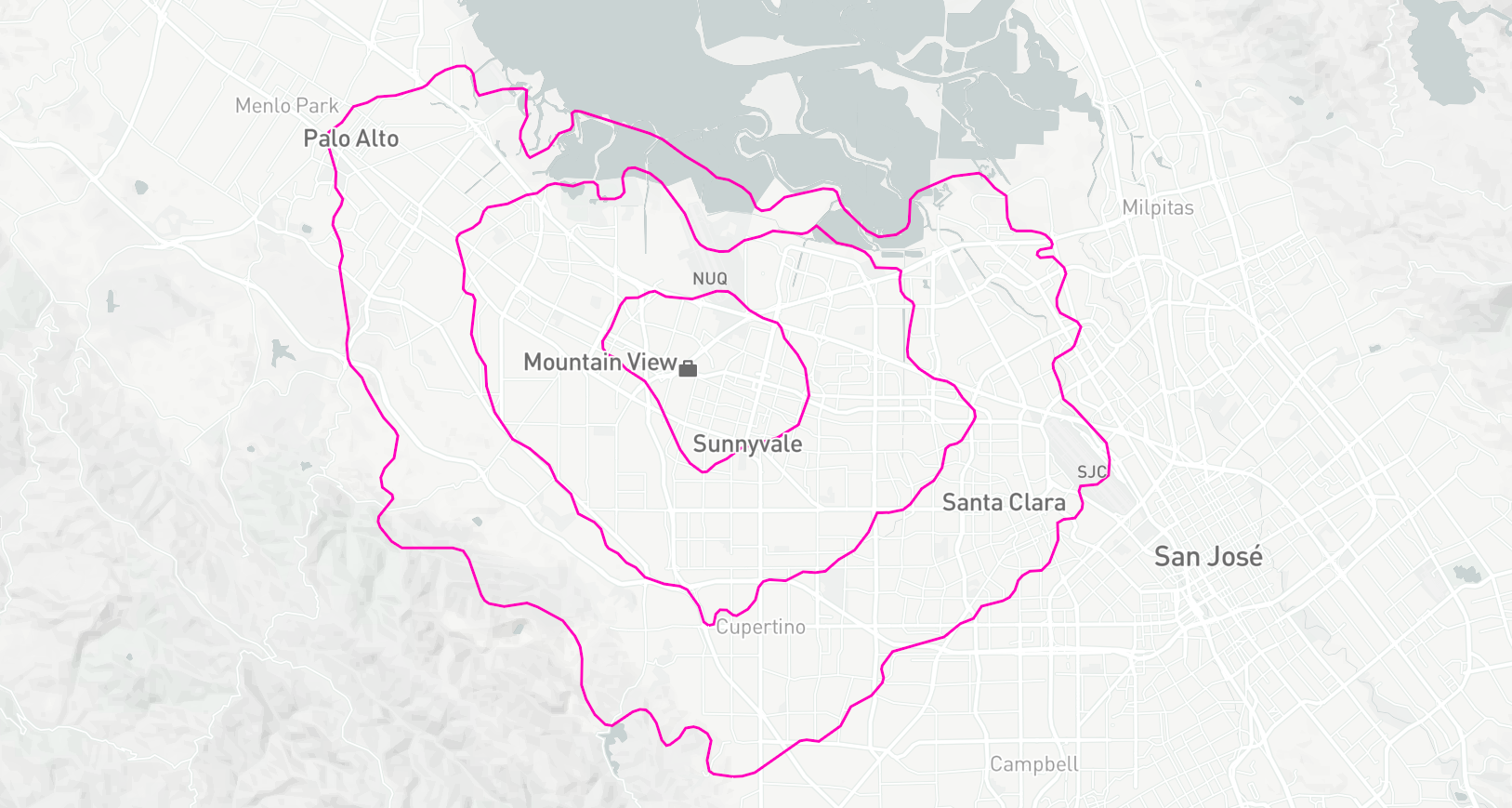
There's a few neat things that stand out:
- I can live further away if I go south or northwest. This is probably because of bike-friendly routes: Steven's Creek bike path heads directly south from work, and there's a couple of bike routes from Mountain View to Palo Alto with barriers to cars.
- It takes 15 minutes to bike to downtown Mountain View, even though it's less than 2km in a straight line. Within that distance there are two major highways as well as train tracks for both Caltrain and VTA, all with limited crossings for cyclists.
The code for this project is on GitHub. My approach was to build a grid of points on the roads around work, compute the bike time for each one, and take contours of the resulting data.
Map Data
I needed two different geographical data sources:
- Directions data, for querying the real travel time between two points.
- Map data, for finding valid road points to query.
Google has an API for this sort of thing, but the number of requests is limited and you don't have any control over how the travel times are calculated.
Instead I used Project OSRM, an open source routing project that uses OpenStreetMap data to give travel directions. I pulled all my road bike journeys from Strava and used the average speed for the bike travel times. I also assigned a large penalty for intersections, as I've found that many traffic lights around here don't recognise bikes and have long cycle times.
Building a Grid
I used a square grid of uniformly spaced latitude and longitude values. Because of the Earth's not-quite-spherical shape, a uniform grid results in two errors (which unhelpfully work in the same direction so don't cancel out):
- Longitude values are closer together at higher latitudes.
- The Earth's radius gets smaller at high latitudes, making longitude values even closer together.
Fortunately, the difference isn't much for this project, it works out to about 0.5% over a 40km grid.
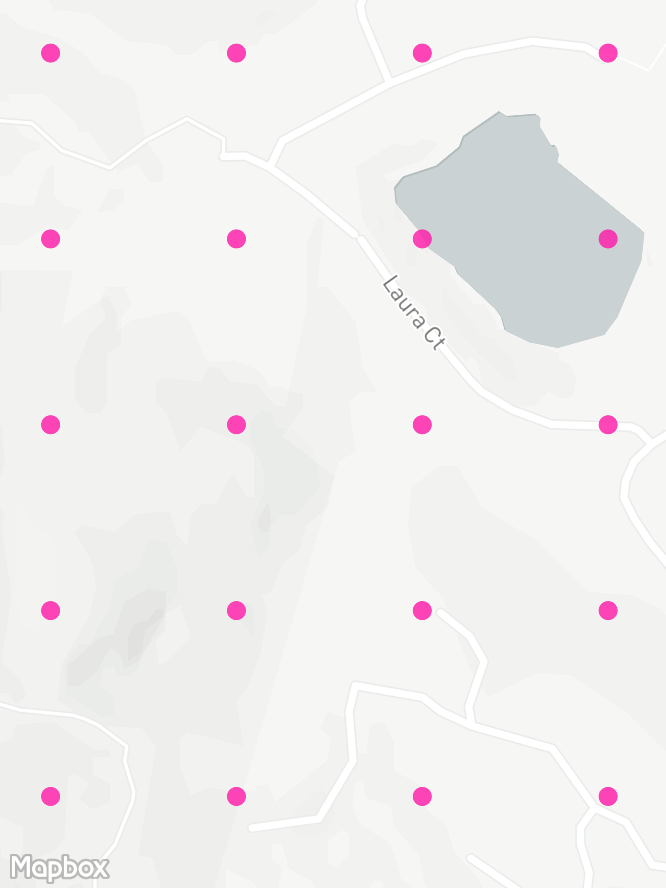
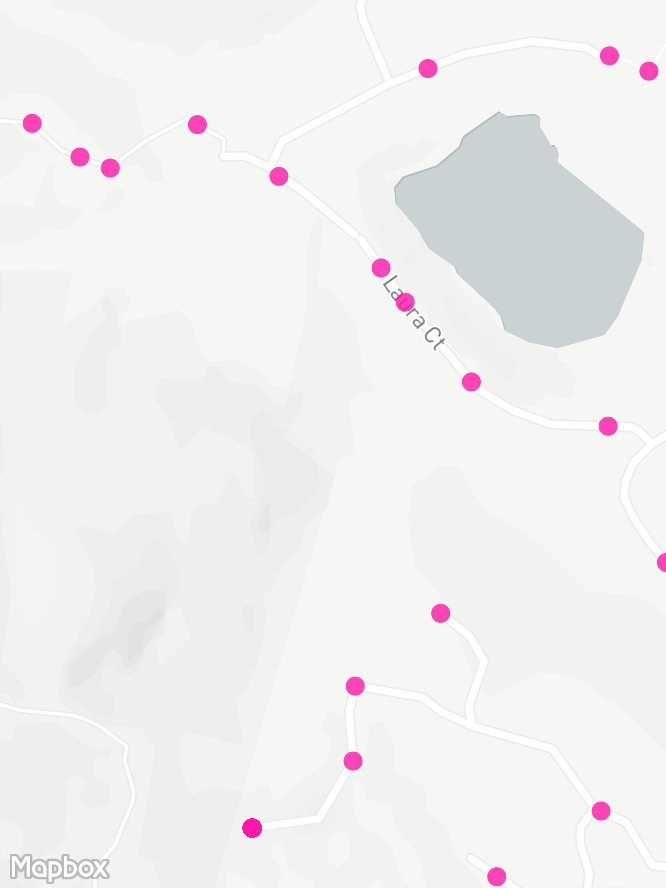
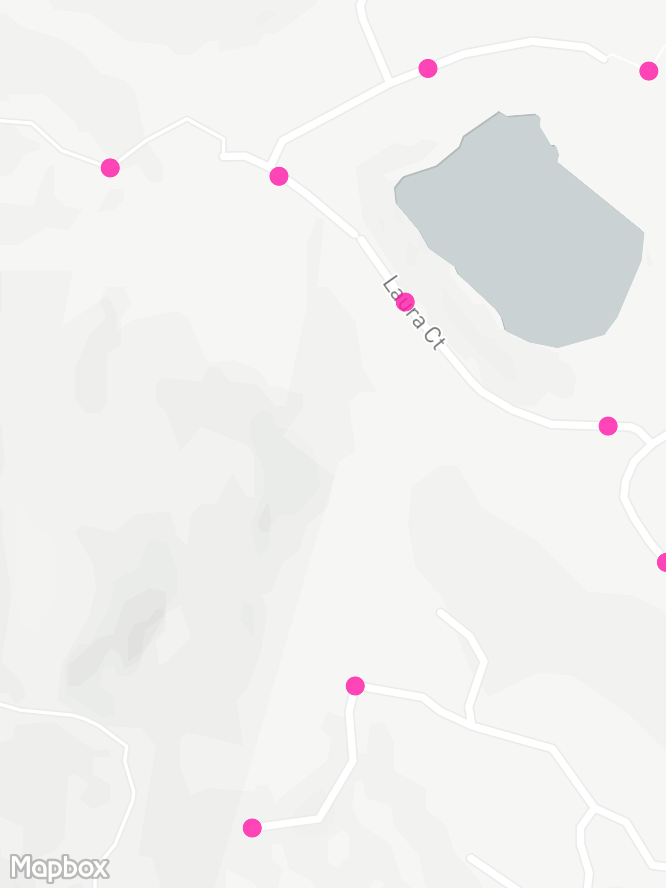
A bigger problem is that when you pick a point randomly on a map, there's a good chance it won't be somewhere you can bike to. Silicon Valley is full of stuff like buildings, airports, and ponds. So I fed the grid into OSRM and replaced each point with the nearest valid biking location. This mostly worked, though I had to manually tidy up lots of maintenance tracks around the shoreline that are incorrectly tagged as public access. My next project is to figure out how to contribute to OpenStreetMap.
Shifting my grid like this loses the uniformity. Large forbidden areas like the NASA airbase result in heaps of points getting redistributed just outside the boundaries with much higher density than the rest of the grid. This isn't really an issue, but mostly to keep the plots clean I pruned the resulting grid by dropping any points that were too close to another point:
for point in points
for neighbour in points
if euclidian_distance(point, neighbour) < threshold
remove neighbour from pointsHere's the development of the grid in an area with some forest and a lake. There's a hikers-only trail in the bottom-left that OSRM correctly avoids snapping to, with the rest of the roads and tracks evenly covered by points.
Travel Times
I fed the evenly-spaced grid into OSRM to find the travel times:
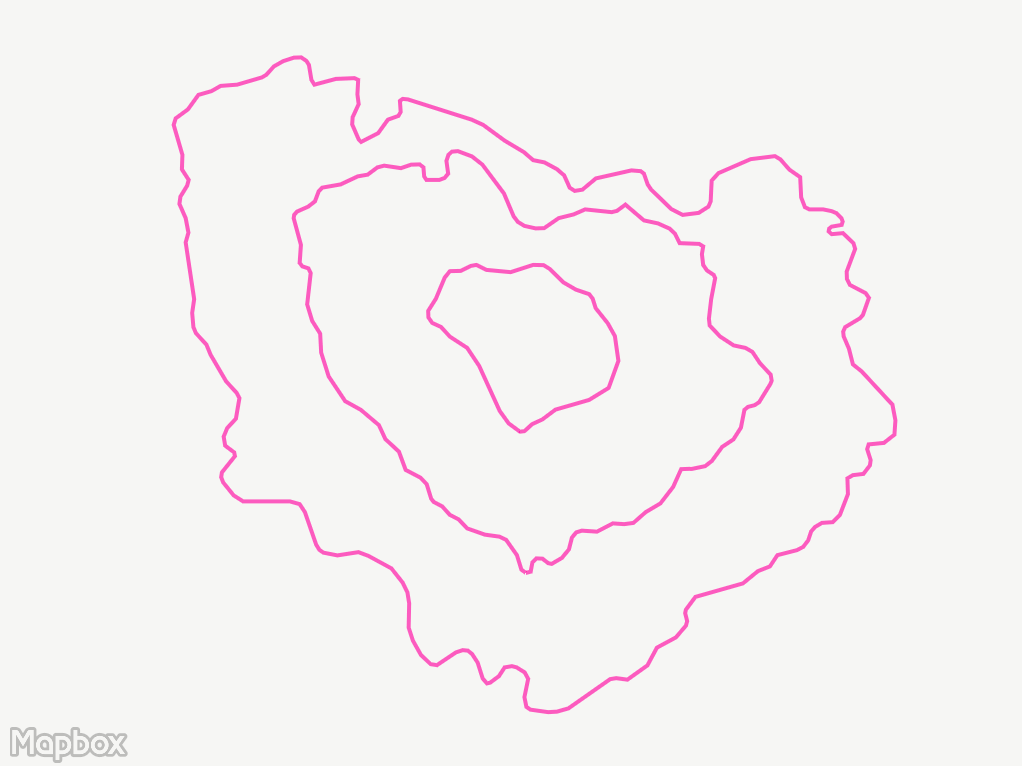
Contouring
The resulting contours are overly detailed, and have weird varying scale thanks to the non-square grid and areas without points. I tidied up the lines by linearly interpolating back to a square grid, and applying a Gaussian blur to the travel times.

Stray Observations
- OpenStreetMap is a fantastic project. I can't think of any open dataset that comes close in terms of size or quality.
- OSRM is pretty neat too. It calculated 1000s of directions per second. Over HTTP, in a Docker container, in a VirtualBox machine, on an old laptop. It would be interesting to do a comparison with the Google Directions API to see how different the travel times are. (Update 2018-04-01: I contributed to a research paper that looks into this! You can find it here: Evaluating urban accessibility: leveraging open-source data and analytics to overcome existing limitations.)